A lot has changed in the fifteen years that I have been developing websites. The biggest changes happened in the browser, completely restructuring how normal web services are built. Now everybody expects your website to have at least a few dynamic elements, be it your login form, your shopping cart or a contact form.
Status Quo
Some websites are actually web apps, which means that they can be developed completely differently and be written as browser apps that only communicate with the server to get the dynamic data. In this case, the web server is only in charge of providing the app itself and exposing some API (mostly a JSON API) the app can consume. Webmail services, task trackers, calendars etc… are good examples of this. They are not what this post is about.
Typical Websites
Most websites can’t and shouldn’t be built like web apps, since they need to be crawlable by search engines and want to be displayed as fast as possible instead of requiring the user to first download the app (that can be a few megabytes).
This is why the approach for normal websites is typically to use a web server to generate HTML sites and provide all the dynamic functionality with HTML. You would then have a normal HTML login form, which posts the data to the server, menus that are rendered differently on the server depending on if the user is logged in or not, displaying session info, etc…
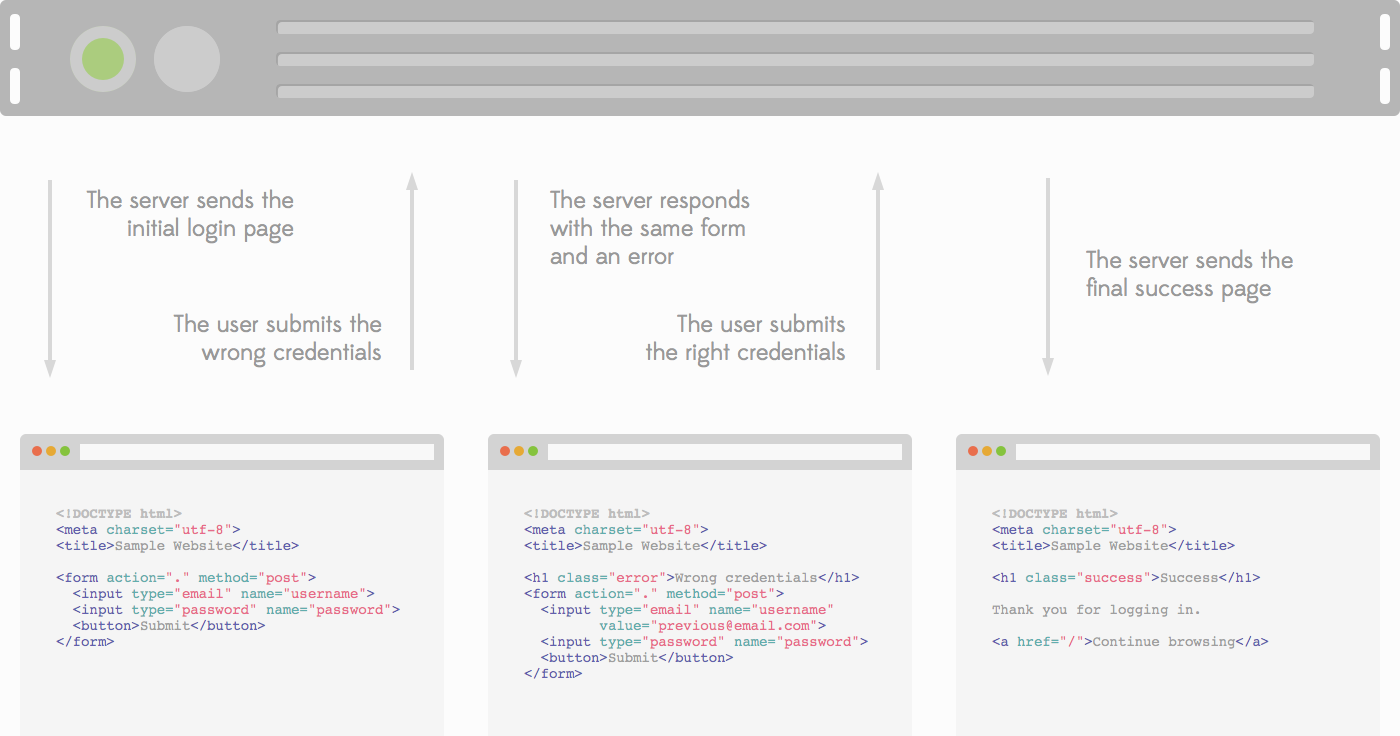
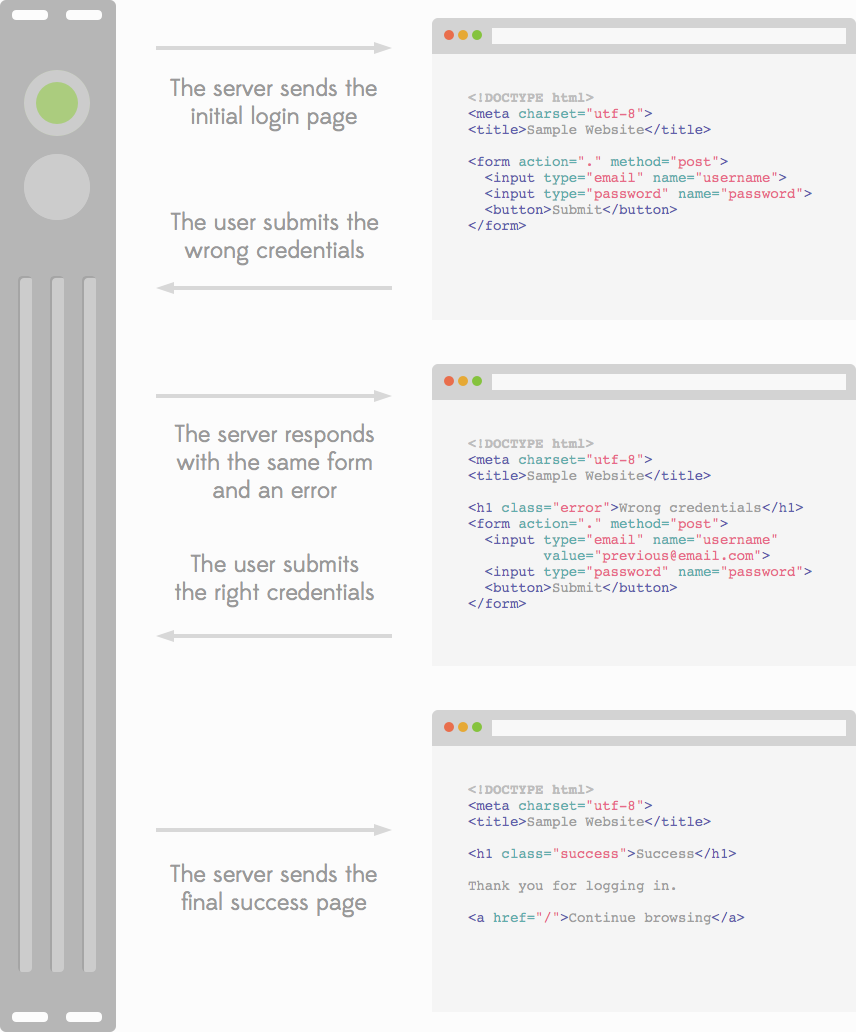
In a second step the website is “modernised” by adding JavaScript to give the website a snappier feel. The login form gets replaced so the user sees a nice spinner when logging in, some items are replaced to be loaded right in the browser to avoid having to reload the whole page and so on.
This approach is typically taken because it creates crawlable pages that can even be accessed with browsers that don’t have JavaScript enabled or are too outdated to properly execute your JavaScript.
This approach is problematic for multiple reasons though:
- You suddenly have to maintain two code bases: the HTML-only variant, and the JavaScript on top of it
- There’s a lot more overall complexity since your JavaScript needs to interact properly with your HTML version (if the HTML changes, the JavaScript might break)
- In most cases the cool JavaScript variants will never make it, because there is already a working HTML implementation, and there are more important things to do than provide a better version of an already existing feature
So in order to also have an HTML only version, you actually create a worse website for 98% of your users to accommodate 2%.
This is where the concept of stateless HTML comes into play.
What is it about?
When I talk about stateless HTML I mean that everything representing a user state (authentication state, geographic position of the user, etc…) should not affect the HTML you render. In other words:
Every user should get the exact same HTML for the same URL, regardless of state, geographic location or time
 The first thing to do is think of which parts need to be crawlable by search engines. In the case of a recipe website, the “About” page and the single “Recipe” pages would be a good example of pages that need to be discoverable when people search for them.
The first thing to do is think of which parts need to be crawlable by search engines. In the case of a recipe website, the “About” page and the single “Recipe” pages would be a good example of pages that need to be discoverable when people search for them.
Everything that represents data that is not affected by who is looking at it and from where.
 The user menu (login, my account, my recipes, etc…), recipes that might suit the user's taste, a contact form and everything that is user specific and dynamic are examples of content that do not need to be included in your HTML.
The user menu (login, my account, my recipes, etc…), recipes that might suit the user's taste, a contact form and everything that is user specific and dynamic are examples of content that do not need to be included in your HTML.
Instead of generating HTML for it, build this functionality on top of your other HTML pages fully with JavaScript.
A good and easy-to-understand example of this concept is this blog – colorglare. All pages are purely static (they are served by GitHub as static HTML pages). Every user and every search engine get the exact same page every time, which allows GitHub to be very efficient in serving the page. On the bottom of the page you have dynamic content though: the message board. In the case of colorglare, I chose to go with disqus so I didn’t have to implement anything. The whole message board is loaded at runtime with JavaScript and doesn’t affect the HTML at all.
So you can see that this concept is nothing new.
Advant
Apart from the things listed in the previous section – which outlined that writing stateless HTML and adding dynamic functionality with JavaScript dramatically reduces the complexity and maintainability of your webapp – a few additional advantages need to be highlighted:
-
Performance. Serving static HTML sites can be heavily cached (by the browser or a load balancer). They only need to change when the content changes, which normally happens rarely.
-
More robust hosting. By completely separating your static content from your dynamic content, your HTML sites are less prone to failure. Depending on the webapp you build, your site could even be served properly if your database crashed, only disabling all authentication and dynamic content (which is far better than your whole page displaying a “database error”).
-
Better user experience. In the next section I’ll explain how stateless HTML can drastically improve the UX of your webapp.
Taking it to the next level
In most cases, pages are more complex than adding a message board. You often have authentication, account management, shopping carts, rating systems, etc… At this point, most developers will start implementing this functionality, and they normally start writing the HTML for it.
In this section I will try to paint the complete picture of how a fully functioning stateless HTML website would work, and what UX benefits you get from it.
Generating the HTML pages
First of all, you still need to create your typical HTML pages. I will give a very simple example of how such a page could look like:
<!DOCTYPE html>
<meta charset="utf-8">
<title>Lacebook – A website dedicated to shoelaces</title>
<link rel="stylesheet" href="style.css">
<script defer src="app.js"></script>
<nav>
<a href="/">Home</a>
<a href="/about">About</a>
<a href="/laces">Laces</a>
<div class="account-menu">
<!-- This will be handled by JavaScript -->
</div>
</nav>
<section id="main">
<!-- This is where your content goes -->
<h1>Welcome to Lacebook!</h1>
The best online resource for shoelaces.
</section>
<footer>
Copyright 2014
</footer>
Now, as soon as your page loads, the JavaScript (in this case app.js) gets executed and does the following things:
- Check if the user is logged in (with cookies and/or an AJAX request to the server)
- Create the appropriate
.account-menucontent (depending on the user authentication state) - Create all the additional JavaScript features (for example, if you are on a Shoelace page, your JavaScript might go over, and add rating functionality)
- Parse the document to find all relative links, pointing to other pages
I think that all of those points are pretty obvious, except for the last one, which is the subject of the next chapter.
Load all content dynamically
By putting all your content in the #main section, and always serving the same HTML blocks before and after, you make it possible to dynamically load your content and simply exchange it for every page, without needing to implement another representation of your content on the server.
When your site is loaded, your JavaScript parses the document and looks for all links that point to other HTML pages on your site, for example: /laces.html, /laces/striped-laces.html, /home.html, /about.html etc…
You then attach a click event handler on those links, “disable” the default behavior (by calling event.preventDefault()) and add your own click handler.
What the implementation should do, is:
- Create an AJAX request to the location (eg.:
/about.html). - Change the URL in the browser with the history API (this way, the back and forward buttons still work in the browser).
- Show a loading animation that the content is now being loaded.
- When the content is loaded, parse it to extract the contents of
#main(you can help yourself there by adding markers in your HTML) and replace the content of your current#mainsection with the one you just loaded. - Make sure that you handle all the links in your new
#maincontent so they will act the same and fire off any JavaScript required for the page that just loaded.
Since all your pages are static HTML files anyway, you just get this “in page loading” functionality for free. Your links are still completely valid (you can just reload the page or send the link to someone else), there is no additional maintenance of two separate versions (the one to be served as pure HTML and the one that gets loaded with AJAX), and the initial delay of showing the account menu or determining the user’s authentication state will not be reproduced since the page is not actually reloaded.
The long-lasting struggle with slow browser adoption and stale browsers (notably IE6) is also a thing of the past, allowing developers to actually use modern features without needing to implement fallbacks for all of them to support their customers.
Of course, if you think that it is imperative that even users with disabled JavaScript must be able to access the dynamic features on your page, you need to implement an `HTML` only solution as well.
Just keep in mind that they are a minuscule minority and that there are only a few websites left that still function without JavaScript.
Summary
As stated before, none of this is really new. The main purpose of this post was to provide strict guidelines on how to build your web application in order to get the best result for the least effort:
- Write stateless HTML
- Build everything else with JavaScript
- Handle page loads transparently with AJAX by loading and parsing your HTML files
To see all of this in action, I created a proof of concept demo page. You can view the JavaScript code at GitHub.